Lorenzo Alberton
« Articles
DataSift and Data Delivery: PUSH
Abstract: A journey into optimising data delivery:
In my previous article I explained a few of the techniques we used at DataSift to optimise Hadoop by improving parallelism and scheduling of queries and by moving less data around.
While these changes led to performances anywhere from 60 to 100 times faster than real-time, they're still just the beginning.
Improving the User Experience
After optimising the storage layer, we turned our attention to API usability, and we felt the API was still to clunky, since it involved a lot of polling and too many stages (prepare query, schedule, wait for completion, start export process, wait for completion, download the results from files, decompress the files, parse the data). It wasn't anywhere near usable in an automated way, so we went once more back to the drawing board.
The intuition was to part from the "conventional" way of running Map/Reduce jobs, and to stream the results directly to the customers, as soon as the incoming messages matched a filter, instead of sending them to the Reducers and back to HDFS. Again, we were able to greatly improve responsiveness and the user experience, by putting less load on the cluster (nice side-effect) and by offering data as a stream just like the real-time streams we already deliver.
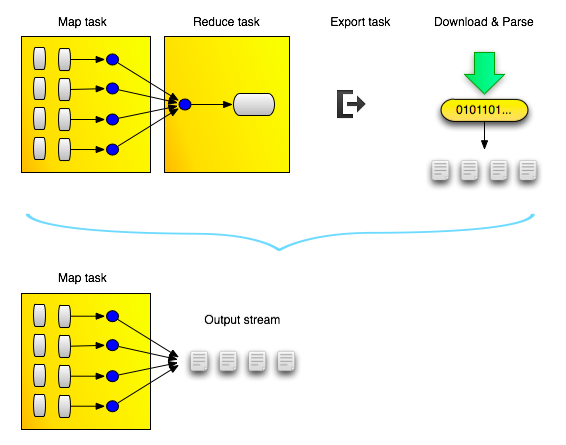
Improving delivery
The final piece of the puzzle was to improve the delivery itself. Not everyone wants to be connected 24/7 to a socket, and the WebSockets protocol might be problematic in corporate networks, where firewalls and proxies usually strip some HTTP headers, hindering a proper communication. Also, given how fast we now scan our Twitter archive, the output channel might see huge volumes of traffic, since we deliver hours worth of tweets in the space of a few seconds, and not everyone can sustain such a high incoming throughput. Even the network itself might be clogged up, especially in trans-continental links (a problem known as long fat network). Thanks to an epic analysis of one of our awesome DevOps, we solved the latter problem by dynamically tuning TCP settings depending on the network latency and throughput, and by creating adaptive stream buffers: when the outgoing stream is high volume, we batch messages within half a second to have a bigger TCP packet and maximise the payload, while keeping the latency very small. When the volume of outgoing message decreases, we skip the batching, cutting the latency to zero. We also invested in serious networking gear to improve communication within our cluster and the internal services, and in dedicated transatlantic links to kill latency and connectivity problems between the UK and the US.
Introducing PUSH
Optimising the communication and investing in better networking infrastructure were necessary steps, but didn't really solve all connectivity and reliability problems that were protocol-related. So, while live streaming via WebSockets or HTTPStreaming will still available, we went on to implement an alternate delivery system with very clear goals:
- guaranteed delivery of high volume streams that need buffering: never lose a message again because of network hiccups
- better resilience in case of failures/downtimes on the customer's end
- deep integration into existing public or private clouds, popular storage and BI solutions.
Related articles
- NoSQL Databases: What, When and Why (PHPUK2011)
- Kafka proposed as Apache incubator project
- Historical Twitter access - A journey into optimising Hadoop jobs
Latest articles
- On batching vs. latency, and jobqueue models
- Updated Kafka PHP client library
- Musings on some technical papers I read this weekend: Google Dremel, NoSQL comparison, Gossip Protocols
- Historical Twitter access - A journey into optimising Hadoop jobs
- Kafka proposed as Apache incubator project
- NoSQL Databases: What, When and Why (PHPUK2011)
- PHPNW10 slides and new job!
Filter articles by topic
AJAX, Apache, Book Review, Charset, Cheat Sheet, Data structures, Database, Firebird SQL, Hadoop, Imagick, INFORMATION_SCHEMA, JavaScript, Kafka, Linux, Message Queues, mod_rewrite, Monitoring, MySQL, NoSQL, Oracle, PDO, PEAR, Performance, PHP, PostgreSQL, Profiling, Scalability, Security, SPL, SQL Server, SQLite, Testing, Tutorial, TYPO3, Windows, Zend FrameworkFollow @lorenzoalberton