Lorenzo Alberton
« Articles
Musings on some technical papers I read this weekend: Google Dremel, NoSQL comparison, Gossip Protocols
Abstract: Some random comments on Dremel and a benchmark on Key-Value stores. How to evaluate technical papers and read between the lines.
This weekend I finally had a chance to read some of the papers I had collected in the last few days, and I thought I'd share some notes on what I found interesting, drawing attention to some points often overlooked when reading a technical paper.
- Solving Big Data Challenges for Enterprise Application Performance Management
- Dremel: Interactive Analysis of Web-Scale Datasets
- How robust are gossip-based communication protocols?
Solving Big Data Challenges for Enterprise Application Performance Management
The first paper (PDF) is a great performance evaluation of 6 data stores in the context of application performance monitoring (APM). I loved the first paragraphs highlighting the need for APM in large scale enterprise systems, and mentioning different approaches and tools (API-based, like ARM instrumentation, and black-box).
Even after such a long introduction about APM, it's easy to overlook the goals and the nature of the data used for the benchmarks when looking at the graphs: in this case, records have one key and 5 fields for a total raw size of 75 bytes, which is sensible for a benchmark of systems meant to store metrics rather than actual data. So when looking at graphs showing that X is faster than Y, remember under what conditions they were measured.
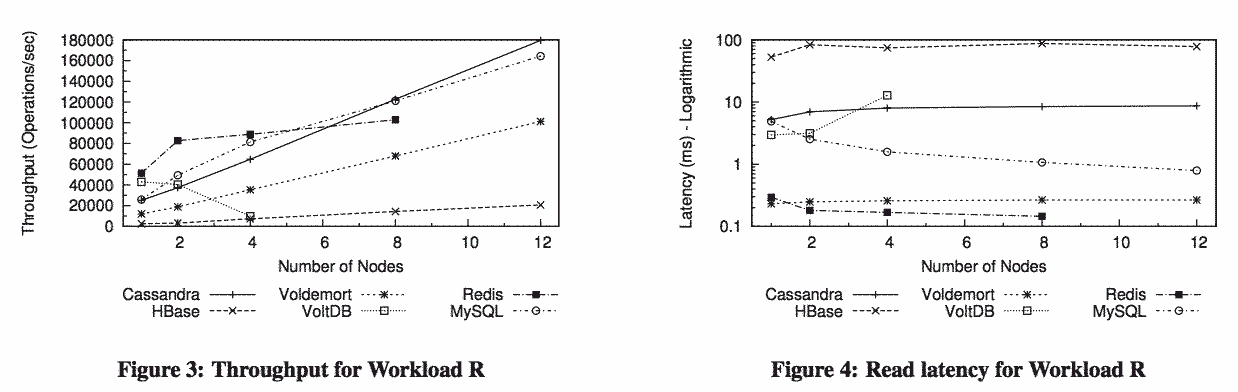
Until the very end, in the last statement about future work, there's no mention about replication, and how it affects performances. In a normal setup, this is one of the first parameters that are considered, and some systems are designed around having a replica factor greater than 1 and optimised for this case, whilst others might suffer when asked to do so.
Likewise, the paper doesn't mention any verification of the stored data. YCSB is a data and workload generator, but does it evaluate data persistence (correctness, data loss, ...) or just throughput and latency?
Again, for the APM use case (i.e. collecting metrics), losing an event in a million might be totally acceptable, but it's important to remember that the systems under evaluation have different persistence and consistency guarantees.
Finally, the results are from averages of tests run for 10 minutes, which is probably not enough for a resilience test.
Albeit most setups have tens or hundreds of nodes, not many benchmarks comparing several systems are executed against as many as 12 nodes, and under different and realistic workloads, which is a very laudable effort from the authors of this paper. It would be nice to evaluate the degradation in performances of each store past the 12th node: I'd be very interested in seeing the breaking point for traditional databases that weren't designed to be distributed. I must say MySQL is behaving incredibly well when a scan is not required, unlike VoltDB whose performances peak at 1 node and crumble at 4 nodes (so much for "linear scaling"). In VoltDB's defence, synchronous queries and scans as done in the YCSB client are quite inefficient, as are for MySQL (see here and here). As the paper notes, HBase is really difficult to configure properly, and most of the apparently poor results are likely due to the default HBase client, which we also found to be a real bottleneck.
I really appreciated their mention of disk usage in the different stores, given the same amount of input data; it's in line with our own experience at DataSift. When dealing with lots of data it might be an useful piece of information to consider for capacity planning / hardware provisioning.
One note about disk usage and data compression in the paper startled me a bit: they say that obviously disk usage can be reduced by using compression, which however will decrease throughput and thus it's not used in their test. This might be true for their specific use case, but it's plain wrong when size and amount of data grow, in fact compression usually improves throughput (less data to scan, more records fit in a memory page).
Finally, it would have been nice to mention bandwidth usage within the nodes in the cluster, as this bit us a few times in the past, and was important enough for us to invest in serious Arista networking gear.
Dremel: Interactive Analysis of Web-Scale Datasets
This is a paper I read more than once since it might soon become seminal like the BigTable one. Dremel is a scalable query system for read-only nested data, used at Google since 2006, and offered as web service called BigQuery.
The paper has a few interesting take-aways. The first big win in query speed, if you're only interested in a few fields in a record, is obtained by moving by record storage to columnar storage. To make a parallel with the RDBMs world, this is exactly the reason why indexes exist: if you don't have to do a full table scan but only need to evaluate a single field, expect huge performance improvements. Also, columnar formats compress very well, thus leading to less I/O and memory usage.
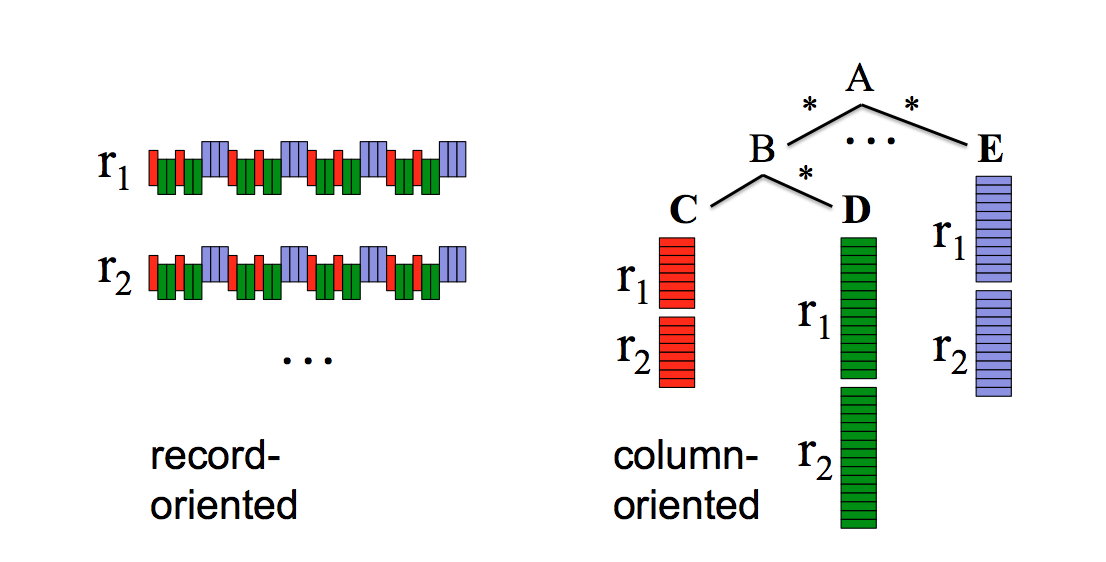
Of course this is nothing new, many commercial and open source implementations exist with column-oriented storage layout capabilities, like Vertica, Infobright, and to a certain extent HBase and Cassandra.
The difference is Dremel's capability of handling nested data models, which explains the novel data representation. And the data representation is probably the first hard bit to grasp as it's not intuitive. I'd suggest carefully reading the explanation and the algorithm in the Appendix.

What I really like about Dremel is the explicit trade-offs made to obtain the incredible query speed at scale:
- A limited query capability (no JOINs?) to optimise latency (then again they have Sawzall for complex queries). While not as expressive as SQL or MapReduce, Dremel really shows its power in tasks like data exploration and simple statistics. The limitation makes it possible to have a simple and very effective query rewriting and execution plan that scales beautifully (also have a look at FlumeJava). Specialisation FTW.
- Option to trade 100% accuracy for much lower latency when approximate results are acceptable. This is the result of the observation that a small fraction of the tablets take a lot longer than the rest, slowing down the query response time by an order of magnitude or more. Ignoring "stragglers" leads to much faster responses.
One last observation is that column-oriented DBs are notoriously very slow at constructing rows from the column-based data, and they really shine when the number of fields to analyse/retrieve is small. Dremel promises gains up to an order of magnitude when reading few fields, with crossover point laying at dozens of fields. In other words, it's not suitable when the application needs to fetch entire records with 100+ fields.
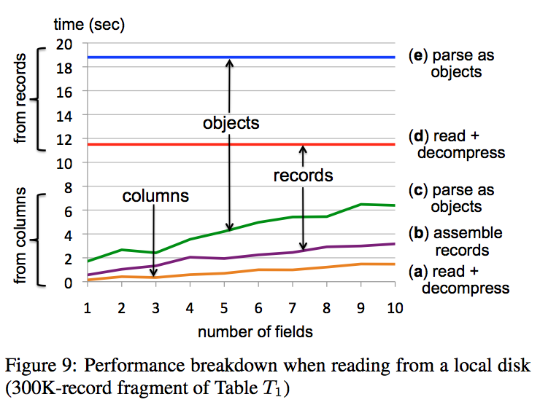
Even with these limitations, the interest for such a tool is obviously huge. I'm aware of two Open Source implementations: OpenDremel/Dazo and Apache Drill. I can't find any code for either, the first one seems an abandoned project, whilst the latter is probably still only hosted within the MapR repositories.
* Update 2012-09-17: OpenDremel and Apache Drill merge efforts
As a further reading resource list, in addition to Dremel, Google is also working on another column-oriented datastore, internally called PowerDrill (apparently, Google has a tradition of choosing names of wood-processing tools for "logs" analysis).
How robust are gossip-based communication protocols?
Gossip protocols are often used to make distributed systems converge to a consistent state by broadcasting messages about recent changes in all nodes.
This short paper exposes some of the assumptions under which gossip protocols are supposed to operate, and discusses how without them a gossip protocol might become unreliable or even cause of an internal denial of service.
Some of the assumptions:
- Having global membership
- In a gossip protocol, participants gossip with one or more partners at fixed time intervals
- There is a bound on how many updates are concurrently propagated
- Every gossip interaction is independent of concurrent gossiping between other processes
- Any two processes can discover each other independently of the gossip mechanism
- Processes select gossip partners within a round in an unpredictable random-like fashion
A must read if you use Cassandra, Riak or a system relying on gossip protocols. If you want to dig further into the scalability limits of distributed protocols, here's a somewhat heavier read.

Latest articles
- On batching vs. latency, and jobqueue models
- Updated Kafka PHP client library
- Musings on some technical papers I read this weekend: Google Dremel, NoSQL comparison, Gossip Protocols
- Historical Twitter access - A journey into optimising Hadoop jobs
- Kafka proposed as Apache incubator project
- NoSQL Databases: What, When and Why (PHPUK2011)
- PHPNW10 slides and new job!
Filter articles by topic
AJAX, Apache, Book Review, Charset, Cheat Sheet, Data structures, Database, Firebird SQL, Hadoop, Imagick, INFORMATION_SCHEMA, JavaScript, Kafka, Linux, Message Queues, mod_rewrite, Monitoring, MySQL, NoSQL, Oracle, PDO, PEAR, Performance, PHP, PostgreSQL, Profiling, Scalability, Security, SPL, SQL Server, SQLite, Testing, Tutorial, TYPO3, Windows, Zend FrameworkFollow @lorenzoalberton
2 responses to "Musings on some technical papers I read this weekend: Google Dremel, NoSQL comparison, Gossip Protocols"
gggeek, 03 September 2012 14:50
Interesting, as always! Hope to have time to read at least the 1st paper you mention...
Phill, 04 September 2012 15:32
Good analysis, especially the paper on Gossip Protocols